The most interesting change is another key-defining feature of Seaside: the ability to create a flow of components in normal code. While I agree with critics that this is rarely useful in web applications, it is technically an interesting challenge to implement in many programming language; and I think with Dart we can get quite close.
Imagine we want to ask the user for two numbers, and then present the sum. This is very easy to do on the command-line or with a desktop application, but on the web it turns out to be quite involved. Essentially I’d like to write:
a typed mixin CanAnswer<T> that can be added to components so they can answer values of type T;
an abstract component class Task that can be used to describe the flow by defining a run method; and
a bunch of helper methods to call other components, and to answer results back to their caller.
This works out of the box. Unfortunately Dart Futures are not resumable, and the back button causes a server exception. Dart supports the creation of custom Future classes, maybe there is a way to tweak the system by using a custom implementation instead?
In any case, easy enough I can use continuation-passing style that works as expected: both for splitting a session into multiple paths and with the back button:
The component model of Seaside is great; so are the callbacks and the state handling. Replicating these core features in Dart turns out to be strait forward:
For the web-server I use the shelf package. Request handlers are specified using functions or function object that receive a Request and return a Response. Our application is such a function object.
The Application is the primary request handler. It is configured with a component factory to create new sessions with a root component; and knows how to dispatch requests to existing sessions.
The Session remembers the root component and its continuations. For incoming requests it activates the right continuation and renders the resulting output.
The Continuation snapshots the application state on creation, and restores the state when it is resumed. The continuation also creates the callback URLs and remembers the callback functions that are created during rendering.
The Component is the primary building block of the web application. It defines the generated HTML output (using Dart string interpolation) and the backtracked state (states). Backtracking needs to go through the loops of a HasState interface, because Dart does not support copying and restoring objects out of the box.
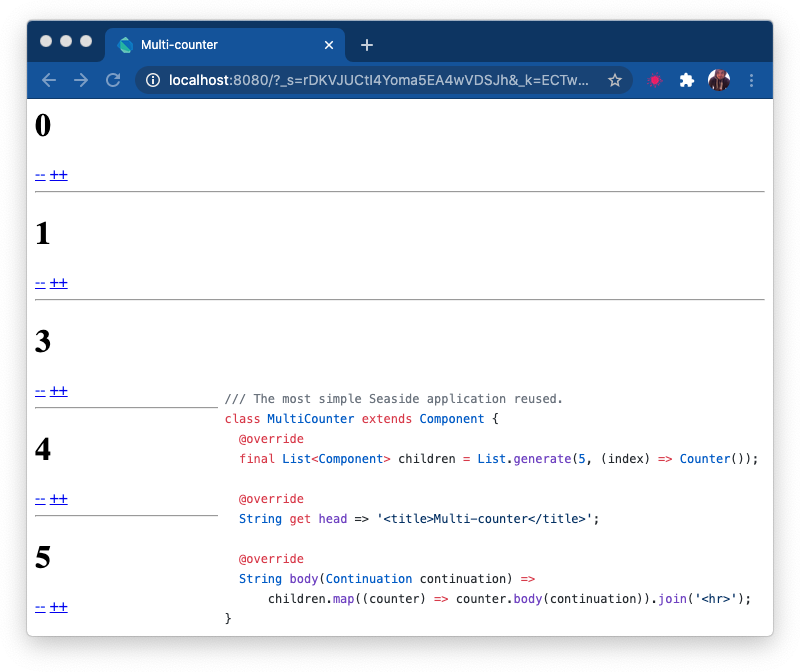
This gives us all (and some more) of the functionality necessary to implement the standard counter and multi-counter applications in Dart. The resulting application code is simple and concise.
The framework code is only 86 lines of code (excluding imports and comments). While the code is far from production ready (sessions for example never expire), it demonstrates how easy the core concepts of Seaside can be converted to Dart. I am not advocating of porting Seaside to Dart as-is, many of the core assumptions the framework took 15+ years ago are simply no longer relevant:
Modern web application use a mix of server- and client-side state and rendered content; keeping everything server-side is convenient, but does not yield a good user experience. Dart gives the opportunity to mix and match client-side and server-side code. Furthermore, all web applications are single page these days. Having something in the core infrastructure that can re-render components client or server-side and at the same time transparently manages the state would be great. I’d love (to build and) use such a web framework.
I am happy to announce initial ports of PetitParser to Java and Dart. The repositories contain complete and usable ports of the original Smalltalk implementation, unit tests and example grammars.
The three implementations are very similar in their API and the supported features. If possible, I tried to adapt common practices and features of the target language. In this blog post I like to point out some differences and design decisions I took.
Production rules
In Smalltalk, the parser that accepts identifiers looks like this:
Instead of the custom operators I use nested function calls. It is visually not as readable as the Smalltalk version, but still it is quite to the point.
In Dart the definition of the identifier parser is similar:
var parser = letter().seq(letter().or(digit()).star());
Alternatively, you can use the overloaded operators of Dart to make it more concise and look like the Smalltalk version:
var parser = letter() & (letter() | digit()).star();
Production actions
To attach a production action to a number parser in Smalltalk one writes:
Due to the lack of closures the Java solution gets a bit bulky. Hopefully this issue will finally be fixed with Java 8. The type declarations are quite nice as documentation of input and output values of the production action:
Luckily Dart has closures, and furthermore we can skip the type declarations:
var parser = digit().plus().flatten().map((input) => Math.parseInt(input));
Composite grammars
For the definition of complex grammars with possibly recursive rules you subclass CompositeParser in all three implementations:
The details of the Smalltalk implementation are explained in this blog post. Production rules are defined as methods and instance-variables of the same name. The parser constructor initializes all production rules to dummy parsers that are eventually replaced by the actual definitions using reflection. As a real-world example have a look at this JSON grammar.
The Java solution is very similar to the one in Smalltalk. To make things a bit more Java-ish, methods are annotated with @Production to mark them as a production. In the future, I plan to avoid the use of inner classes for production actions by introducing new annotation called @Action. Again there is a JSON grammar to look at.
Due to the (current) lack of reflection in Dart I had to come up with something else. For Dart I introduced a DSL that allows one to define productions, reference productions, redefine productions and assign production actions to existing productions. The implementation is simple and I like it much better than the others. The JSON grammar in Dart is pretty concise.
Performance
Comparing the performance of the implementations is interesting. For this preliminary evaluation I took the XML parser and parsed 2000 times a medium sized XML file. This is the ranking:
Java: 815ms (Java HotSpot 64-Bit 1.7)
Smalltalk: 4069ms (Pharo 1.3 on Cog)
Dart: 6156ms (Dart SDK version 13851, M1)
Dart: 7048ms (Dart SDK version 8638)
Dart: 14332ms (Dart SDK version 8344)
Interestingly Java is doing really well, even if I use auto-boxed characters everywhere and didn’t care to optimize the implementation yet.
The Smalltalk implementation is about 4 times slower. With this implementation I worked the longest and I doubt that it can be optimized further.
Dart lost this evaluation, but I am sure that the code can be further improved. I am suspecting that a problem is that Dart has no notion of characters and needs to represent them as integers or single character strings. Also, in Dart there is no efficient way to figure out if a character is a whitespace, a letter or a digit. To do this correctly I had to fall back to regular expressions, which likely kills an otherwise fast VM. The latest implementation works directly with character codes.
Availability
To sum up, the three implementations are open-source and available in their respective public repositories:
In a previous post I described the basic principles of PetitParser and gave some introductory examples. In this blog post I am going to present a way to define more complicated grammars. We continue where we left off the last time, with the expression grammar.
Writing parsers as a script as we did in the previous post can be cumbersome, especially if grammar productions that are mutually recursive and refer to each other in complicated ways. Furthermore a grammar specified in a single script makes it unnecessary hard to reuse specific parts of that grammar. Luckily there is PPCompositeParser to the rescue.
Defining the Grammar
As an example let’s create a composite parser using the same expression grammar we built in the last blog post:
Every production in ExpressionGrammar is specified as a method that returns its parser. Productions refer to each other by reading the respective instance variable of the same name. This is important to be able to create recursive grammars. The instance variables themselves are typically not written to as PetitParser takes care to initialize them for you automatically.
Next we define the productions term, prod, and prim. Contrary to our previous implementation we do not define the production actions yet; and we factor out the parts for addition (add), multiplication (mul), and parenthesis (parens) into separate productions. This will give us better reusability later on. We let Pharo automatically add the necessary instance variables as we refer to them for the first time.
Now that we have defined a grammar we can reuse this definition to implement an evaluator. To do this we create a subclass of ExpressionGrammar called ExpressionEvaluator
For those that missed my PhD defense, below the video recording of the event. Thanks go to Tudor Gîrba and Jorge Ressia for recording it. The slides can be found on SlideShare.